
Six Efforts to Improve Spark Performance

Today, Reynold Xin released more details about what is now called Project Tungsten (previously called Project Iron) and it consists of three parts:
Project Tungsten
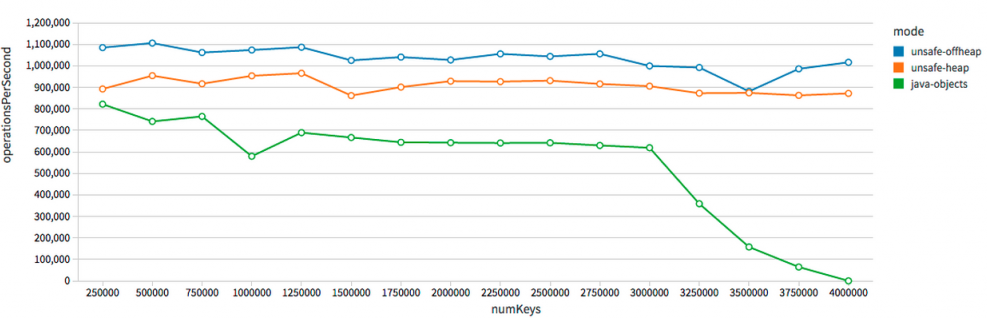
1. Native memory access with sun.misc.Unsafe (off the JVM heap)
In the initial implementation, a native-memory replacement has been tested for Java's HashMap, and the chart above shows the Java HashMap petering out after 3 million keys.
2. Storing 64-bit keys and 64-bit pointers as a 128-bit unit for CPU cache-friendly sort() and groupByKey()
Currently, Spark implements key/value pairs as Tuple2[]s, which like all JVM objects are not "values" (in the compiler sense of the word) and have to be dereferenced. Lumping the key in with the pointer to the value (in the key/value sense of the word) prevents some dereferencing. See Reynold's blog linked above for a nice diagram.
3. Generating JVM bytecode at runtime for faster serialization/deserialization
Evidently according to Reynold's blog, code generation is already being done to evaluate Spark SQL queries, and this would extend the concept to serialization/deserialization. Recall Kay Ousterhout et al found that this, as opposed to disk speed or network speed, was one of the remaining bottlenecks in Spark.
Other Efforts
GPU
As I previously blogged, someone has already demonstrated dropping in a GPU-powered BLAS. Project Tungsten also plans GPU enhancements in the future. GPU is the next logical direction for Spark given a single GPU-powered node has been shown to be 4x as fast as a 50-node Spark cluster.
Sparrow Scheduler
Although in her recent paper Kay Ousterhout downplayed the potential performance improvement from scheduling optimizations, she still indicated 5-10% performance improvement was possible. Years ago, she herself developed the Sparrow scheduler, but that code base has diverged significantly since that prototype and would require major architectural changes such as multiple masters.
IndexedRDD
IndexedRDD would seem to be a holy grail data type for Spark: not only is it an efficient HashMap equivalent of an RDD, but it is also mutable. While available from AMPLab, it has not yet been targeted for any particular Spark release, and some are getting a little testy about waiting for it to appear in an official Spark release.