
Single GPU-Powered Node 4x Faster Than 50-node Spark Cluster

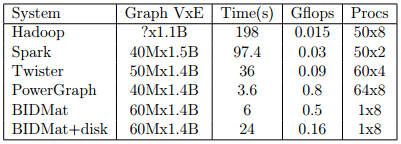
The above chart comes from a new dissertation out of Berkeley entitled High Performance Machine Learning through Codesign and Rooflining. Huasha Zhao and John F. Canny demonstrate that for the PageRank problem, their custom GPU-optimized matrix library they called BIDMat outperforms a 50-node Spark cluster by a factor of four. Their single GPU-powered node had two dual-GPU Nvidia cards for a total of four GPUs.
And BIDMat is just one component of their full BIDMach software stack illustrated below (illustration also from their dissertation).
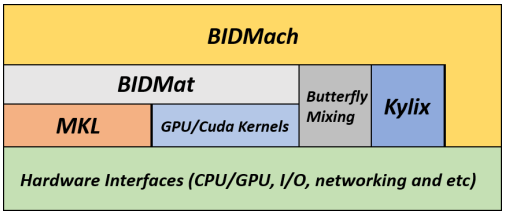
Intel MKL and GPU/Cuda are of course off-the-shelf libraries. Butterfly mixing is a new 2013 technique by the same two authors that updates a machine learning model "incrementally" by using small subsets of training data and propagating model changes to neighboring subsets. They do not state it explicitly, but these network communication diagrams between the small subsets resemble the butterfly steps in the Fast Fourier Transform algorithm.
Kylix is an even newer (2014) algorithm, again by the same two authors, that further optimizes the butterfly approach by varying the degree of each butterfly node (the number of butterfly nodes each butterfly node must communicate with) in a way that is optimized for real-life power-law data distributions.
Finally, part of their overall approach is what they have coined "rooflining", which is where they compute the theoretical maximum communication and computation bandwidth, say of a GPU, and ensuring that their measured performance comes close to it. In their dissertation, they show they reach 80-90% of CPU/GPU theoretical maximums.
By doing so, the authors have turned GPU hype into reality, and have implemented numerous machine learning algorithms using their BIDMach framework. Now it remains to either make BIDMach available for commercial production use, or to incorporate the concepts into an existing cluster framework like Spark.