
Introduction to Apache Drill
With the rapid growth of data and the shift towards rapid development solutions much data is being stored in NoSQL stores such as Hadoop and MongoDB. The infrastructure built upon relational databases that have been used for decades cannot keep up with the volume and scope of data being captured. Further to this SQL is also a really good invention and method for extracting and analysing data that is very widely used. In short it will not be replaced by hierarchical query techniques such as XPATH anytime soon.
In the common case study of Google, the data that Google captured in the early 2000’s was just too large to for the traditional database structure to handle. Google developed an innovative algorithm that divided their data into smaller, more manageable sets of data across multiple machines and mapped the data to come together after required processing is done. They called this algorithm Map reduce, this algorithm was used to develop an open-source platform called Hadoop.
Hadoop is one of many frameworks that has been developed to allow massively parallel computing for fast and cost efficient results. With the massive increase of data being captured from new sources businesses started using old and new frameworks together. The challenge of this occurrence is how to link up all of this information from different sources and different formats to extract the right data for an ad-hoc business case that would yield valuable and rapid results. Google solved this with an innovation they called Dremel. The open source community in tribute then created Apache Drill. Drill solves this relational & non-relational problem by enabling the user to query data across different frameworks and formats to deliver low-latency results that can be interpreted in familiar tools and language.
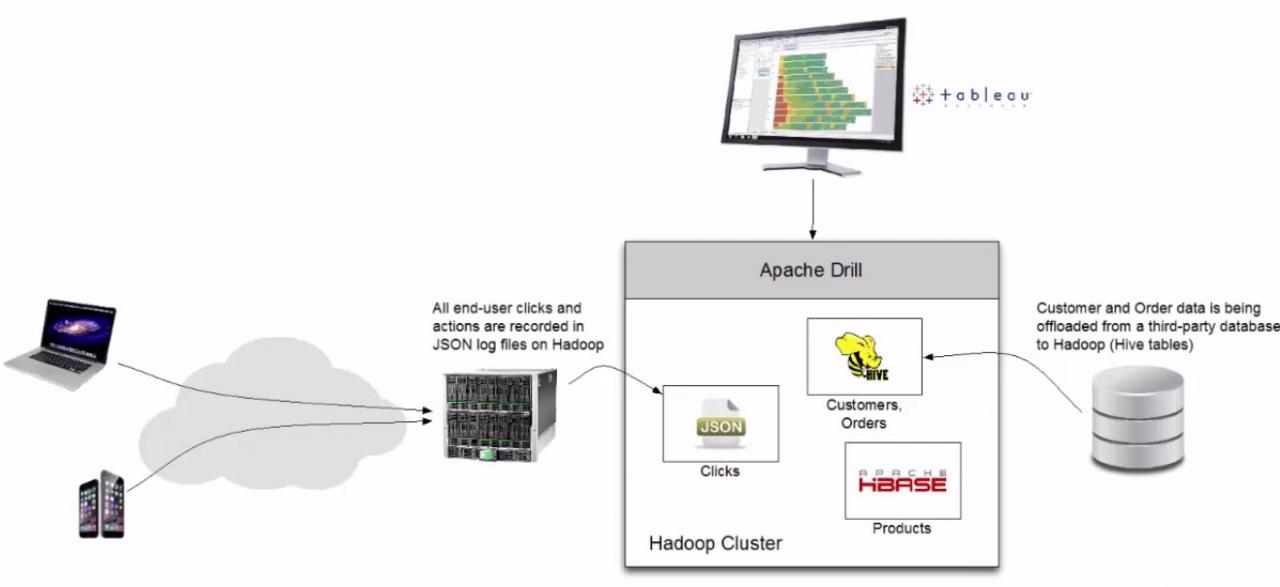
Apache Drill software has a few differentiating features that gives it a competitive edge. It is schema free, users can quickly query raw data without the time consuming and costly task of schema creation and significant IT involvement. Apache Drill is considered to be one of the fastest query engines on the market today. There is no need for data loading, it has specialized memory management that reduces memory footprint and eliminates garbage collections. It also supports locality-aware execution that reduces network traffic when Drill is co-located with the datastore. Lastly, Apache Drill has been developed with the user in mind. The software is easy to install and supports all major operating systems. It leverages user’s acquired SQL skillsets, there is no need to learn a new coding language. It is also integrated to work with popular business intelligence tools such as Tableau, Qlikview, MicroStrategy and more.
Overall, Apache Drill is a software solution that users can implement to leverage their traditional relational data assets alongside newer nosql sources in a quick and convenient way while continuing to use familiar tools and language.
At Data to Value we have been using Drill as a way of accessing GPS track data stored in its native format (GPX) in order to create derived data such as speed and heading. This is great as it enables us to retain the data in a standard format for using in GPX compliant tools whilst also generating the custom analysis that we need to analyse in BI and other visualisation tools. For more visit our website.