
Data Locality: HPC vs. Hadoop vs. Spark

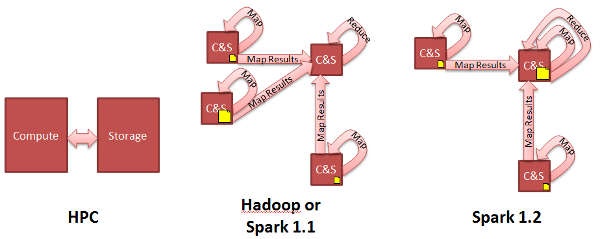
Diagram Notes: 1. Yellow documents are map outputs 2. Not shown is that Hadoop spools map outputs to disk before reduce task reads them, whereas Spark keeps the map outputs in RDDs.
The big advance Hadoop brought over classic High Performance Computing (HPC) is data locality. Hadoop brings the compute to the data. (HPC compensates by having faster interconnects such as Infiniband and high-bandwidth storage.)
The big advance Spark brought over Hadoop is storing data in each node's RAM instead of each node's disk. Spark's leveraging of data locality is very similar to that of Hadoop's: namely, computation is assigned to occur where the data resides.
Except Spark 1.2 is set to improve that a bit. In a just published paper, AMP Lab contributor Shivaram Venkataraman et al propose assigning the reduce task to the node that happens to have the largest map output, thus minimizing data movement.
This advance is currently slated for Spark 1.2, in Jira ticket SPARK-2774
There are other advances described in the Venkataraman et al paper, namely, when sampling subsets of data such as BlinkDB does, Spark could greedily take whatever data happens to be present on nodes with available compute, and call that the sample. There is no set Spark release for that feature, which the paper calls KMN.