
Big Data Analytics Infrastructure


Recent surveys suggest the number one investment area for both private and public organizations is the design and building of a modern data warehouse (DW) / business intelligence (BI) / data analytics architecture that provides a flexible, multi-faceted analytical ecosystem. The goal is to leverage both internal and external data to obtain valuable, actionable insights that allows the organization to make better decisions.
Unfortunately, the amount of recent DW / BI / Data Analytics innovation, themes and paths is causing confusion. The "Big Data" and "Hadoop" hype is causing many organizations to roll-out Hadoop / MapReduce systems to dump data into without a big-picture information management strategic plan or understanding how all the pieces of a data analytics ecosystem fit together to optimize decision making capabilities.
This has resulted in the creation of a new word: Hadump - meaning data dumped into Hadoop with no plan. There are two schools of thought about data collection and storage strategy:
1) Start big data analytics project with a specific use case or problem to solve
2) Start dumping data to store and analyze later
I strongly suggest using both strategies. One is short term for quick results and other for long term value.
Consider only about 30% of all collected data will be valuable. The problem is you do not know what 30% will indeed be valuable. Thus, it is prudent to collect and store all data: structured and unstructured as well as internal and external.
The cost of collecting and storing the data - and data analytics technology - has been significantly reduced and will get cheaper and cheaper.
The cost of analyzing the data for valuable, actionable insights is very high. While machine learning and automation will reduce cost in future, the formula of cheap, abundant data and expensive data science and business analytics will likely remain for some time.
Thus, start a data analytics project to solve a specific problem or to take advantage of an opportunity to demonstrate value. Yet understand the long term value of saving any and all data for future analysis - as the specific use case arises.
More importantly, it is crucial to spend time and resources to develop both an information management strategic plan and decision optimizing processes. Data science knowledge and business processes detailing the collection, storage, analysis and distribution of data is the magic sauce that orchestrates the data tech ingredients.
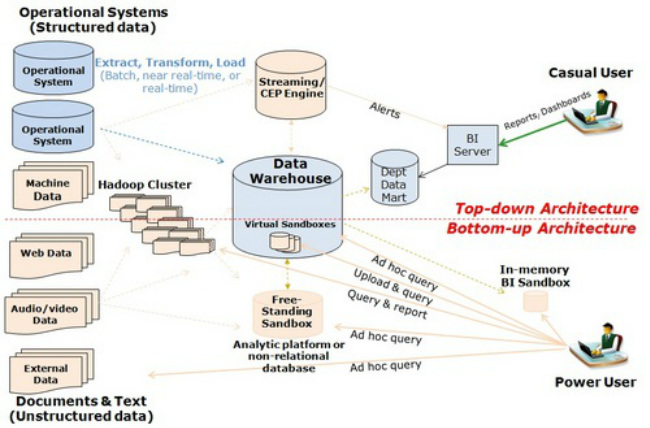
A traditional BI architecture has analytical processing first pass through a data warehouse.
In the new, modern BI architecture, data reaches users through a multiplicity of organization data structures, each tailored to the type of content it contains and the type of user who wants to consume it.
The data revolution (big and small data sets) provides significant improvements. New tools like Hadoop allow organizations to cost-effectively consume and analyze large volumes of semi-structured data. In addition, it complements traditional top-down data delivery methods with more flexible, bottom-up approaches that promote predictive or exploration analytics and rapid application development.
In the above diagram, the objects in blue represent traditional data architecture. Objects in pink represent the new modern BI architecture, which includes Hadoop, NoSQL databases, high-performance analytical engines (e.g. analytical appliances, MPP databases, in-memory databases), and interactive, in-memory visualization tools.
Most source data now flows through Hadoop, which primarily acts as a staging area and online archive. This is especially true for semi-structured data, such as log files and machine-generated data, but also for some structured data that cannot be cost-effectively stored and processed in SQL engines (e.g. call center records).
From Hadoop, data is fed into a data warehousing hub, which often distributes data to downstream systems, such as data marts, operational data stores, and analytical sandboxes of various types, where users can query the data using familiar SQL-based reporting and analysis tools.
Today, data scientists analyze raw data inside Hadoop by writing MapReduce programs in Java and other languages. In the future, users will be able to query and process Hadoop data using familiar SQL-based data integration and query tools.
The modern BI architecture can analyze large volumes and new sources of data and is a significantly better platform for data alignment, consistency and flexible predictive analytics.
Thus, the new BI architecture provides a modern analytical ecosystem featuring both top-down and bottom-up data flows that meet all requirements for reporting and analysis.
Comments
RichardKPack
Fri, 2018/11/30 - 12:30am
Permalink
Re:
Thanks for the great post.