
AWS: The Latest Must-Have Skill To Maintain Unicorn Status

A survey published this week revealed not only do a mere 1% of data scientists claim an advanced proficiency in all five areas delineated by the survey (Business, Technology, Math & Modeling, Programming and Statistics), but there were some specific sub-categories in which most people claimed a novice level of skill, such as Natural Language Processing.
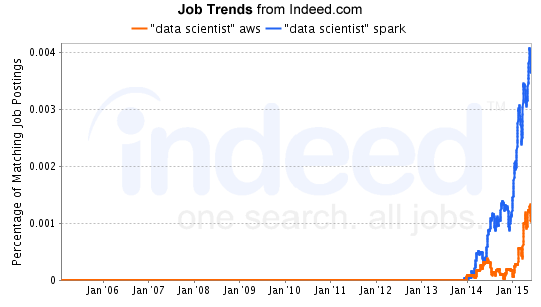
Of course the unicorn is both a myth and a joke by this point, as we've long recognized the need for data science teams, but here is yet another skill data scientists are increasingly expected to have: AWS. The chart above from indeed.com shows the trend of Data Science AWS taking off vertically in the second quarter of this year (2015). By comparison, Spark is old hat to data scientists, have started its upward trend in earnest a year prior.
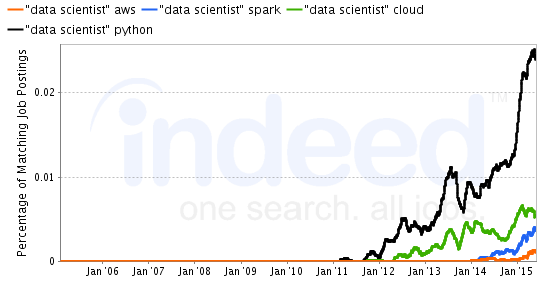
To put that into perspective against a more mainstream data scientist skill, Data Scientist Python started its climb in early 2012. Interestingly, Data Scientist Cloud started its climb a few months after that, also way back in 2012, but one would assume that was more buzzword compliance than an actual skill requirement. Now that we have actual cloud technology available to anyone with a personal credit card, its need is in a vertical climb.
And here's the thing: AWS is shaping up to be an actual unicorn requirement, and might even be reining in a bit the idea of spreading out data science to a team. Whereas before it would be unreasonable to expect a data scientist to provision, install, monitor and manage a Hadoop/Spark cluster (DevOps, in short), now it's reasonable to expect proficiency in AWS and to expect the data scientist to be self-sufficient when it comes to compute and storage needs.