
Row vs. Columnar vs. NoSQL Database Options

I am often asked how to select the right database. The answer is it depends - no one size fits all situations. How do you choose?
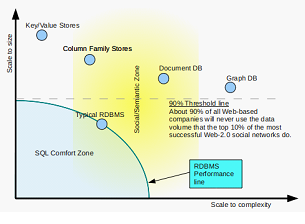
There's no easy answer - choosing the best is difficult because a good developer will want to balance the strength of the project, the availability of commercial support, and the quality of the documentation with the quality of the code.The greatest divergence is in the extras - all will store piles of keys with their values, but the real question is how well they split the load across servers and how well they propagate changes across them.
Note that NoSQL databases have the power to lock you in - that's the price for all of the fun and features.
Then there's the question of hosting. The idea of a cloud service that will do all of the maintenance for you is seductive yet the stakes are higher with NoSQL databases because switching is more difficult than with the SQL databases. There's no standard query language in this world, nor is there a vast array of abstraction layers like the JDBC.

There are some general guidelines that may be useful.
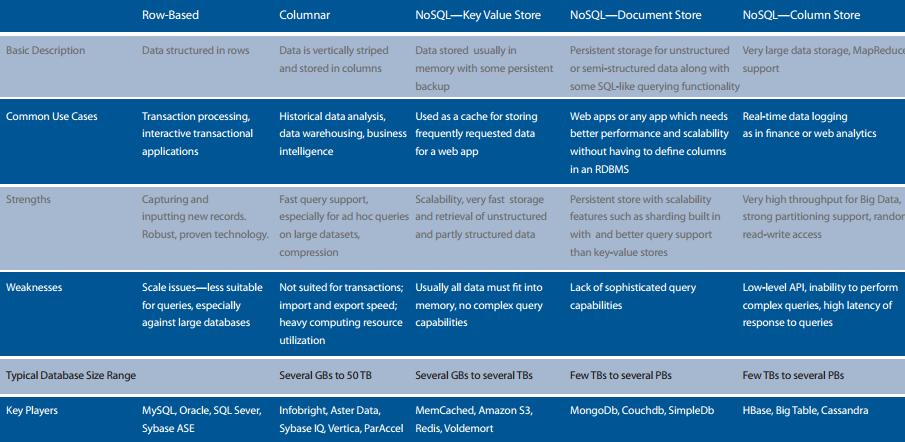
Below is an overview of the major NoSQL databases:
Cassandra
Facebook needed something fast and cheap to handle the billions of status updates, so it started this project and eventually moved it to Apache where it's found plenty of support in many communities. It's not just for Facebook any longer. Many of the committing programmers come from other companies, and the project chair works at DataStax.com, a company devoted to providing commercial support for Cassandra.The heritage of the Cassandra project is obvious because it's a good tool for tracking lots of data, such as status updates at Facebook. The tool helps create a network of computers that all carry the same data. Each machine is meant to be equal to the others, and all of them should end up being consistent once the data propagates around the P2P network of nodes, though it's not guaranteed.
The key phrase is "eventual consistency," not "perfect consistency." If you've watched your status updates disappear and reappear on Facebook, you'll understand what this means.The tool runs in Java as a separate process waiting for interaction. There's already a collection of higher-level libraries for Java, Python, Ruby, and PHP, as well as some of the other languages.Using Cassandra seems relatively simple, but I still found myself getting hung up on several barriers, such as defining a keyspace (which acts as a namespace but for the columns). Getting up to speed takes more than a few minutes because there are more than just the basic routines for storing collections of values. Cassandra is happy with a sparse matrix where each row stores only a few standard columns, and it builds the indices with this in mind.
Much of the complexity in the API is devoted to controlling just how quickly the cluster of nodes moves toward consistency. You can specify the speed of synchronization for columns and collections of values called supercolumns.Getting everything running is now fairly well documented, but getting it running quickly requires a fair amount of both hardware and operating system tuning. The biggest bottleneck is the commit log. Optimizing the way that this is written to disk is the most important part of improving writes. Speeding up the extraction of data involves paying attention to the pattern of reads. Did your old, fancy database do this for you fairly automatically? Ah, don't complain. It's fun to think about the hardware and how it affects your software.
CouchDB
CouchDB stores documents, each of which is made up of a set of pairs that link key with a value. The most radical change is in the query. Instead of some basic query structure that's pretty similar to SQL, CouchDB searches for documents with two functions to map and reduce the data. One formats the document, and the other makes a decision about what to include.I'm guessing that a solid Oracle jockey with a good knowledge of stored procedures does pretty much the same thing. Nevertheless, the map and reduce structure should be eye-opening for the basic programmer. Suddenly a client-side AJAX developer can write a fairly complicated search procedure that can encode some sophisticated logic.
The core of CouchDB is written in Erlang, but the API and interface is all JavaScript or JSON. You won't need to worry about this detail. The JavaScript API only enhances CouchDB's appeal for the average Web developer who can store documents and even entire websites inside the database itself.There's a burgeoning community growing around CouchDB. All of the major languages now have client libraries that simplify the interaction with the database and make it possible to store your data. They don't always expose all of the power of the query function, but that's not necessary for every service. There are also companies like Couchbase that bundle CouchDB into commercial product offerings. Cloudant offers the database as a hosted service and partners with companies like CloudBees to support the code running on the Cloudant cloud. It's getting easier and easier to use CouchDB like a service.
MongoDB
MongoDB is just one of the examples of how JavaScript is taking over the world. The program takes data formatted as JavaScript objects (a format known as JSON) and stores them away. Queries are basic JavaScript functions. It's not much different from using the console of your browser. Well, that's simplifying things a bit. The big difference is that MongoDB will create indices for the columns of your database and return queries faster when the indices are correctly constructed. That's part of your job, by the way. You want to anticipate which indices your users will need.You don't need to speak the subset of JavaScript for this language because there's a big collection of libraries and drivers written for all of the major languages and many of the minor ones.
These libraries are extensive, and some of the major languages have extra layers that wrap and unwrap objects when storing and retrieving them.There's also a fair number of extra tools for working with the database. PHPMoAdmin, a cousin of the MySQL tool PHPMyAdmin, is just one of almost a dozen tools for admins. The proliferation of these tools is gradually erasing one of the standard reasons for sticking with a classic database. As I found more of them, I noticed that everything was more comfortable.
Redis
Like CouchDB and MongoDB, Redis stores documents or rows made up of key-value pairs. Unlike the rest of the NoSQL world, it stores more than just strings or numbers in the value. It will also include sorted and unsorted sets of strings as a value linked to a key, a feature that lets it offer some sophisticated set operations to the user. There's no need for the client to download data to compute the intersection when Redis can do it at the server.This approach leads to some simple structures without much coding. Luke Melia tracked the visitors on his website by building a new set every minute. The union of the last five sets defined those who were "online" at that moment. The intersection of this union with a friends list produced the list of online friends. These sorts of set operations have many applications, and the Redis crowd is discovering just how powerful they can be.Redis is also known for keeping the data in memory and only writing out the list of changes every once and a bit. Some don't even call it a database, preferring instead to focus on the positive by labeling it a powerful in-memory cache that also writes to disk.
Traditional databases are slower because they wait until the disk gets the information before signaling that everything is OK. Redis waits only until the data is in memory, something that's obviously faster but potentially dangerous if the power fades at the wrong moment.The project leaders are still exploring how to expand the project, an intriguing decision because there's more than one official version of Redis from the main team. There's even one official build of Redis that comes with a Lua interpreter and a disclaimer saying that "there is no guarantee that scripting works correctly or that it will be merged into future versions of Redis!" Projects like these are never boring.Redis providers are starting to appear. OpenRedis promises it's "launching soon." Meanwhile, Redis Straight Up charges just $19 per month, plus all of the costs from Amazon's cloud. The service handles the configuration and passes the costs on to you.
Riak
Riak is one of the more sophisticated data stores. It offers most of the features found in others, then adds more control over duplication. Although the basic structure stores pairs of keys and values, the options for retrieving them and guaranteeing their consistency are quite rich.The write operations, for instance, can include a parameter that asks Riak to confirm when the data has been propagated successfully to any number of the machines in the cluster. If you don't want to trust just one machine, you can ask it to wait until 2, 3, or 54 machines have written the data before sending the acknowledgment. This is why the team likes to toss around its slogan: "Eventual consistency is no excuse for losing data."The data itself is not just written to disk. Well, that is one of the options, but it's not the main one. Riak uses a pluggable storage engine (Bitcask by default) that writes the data to disk in its own internal format.
There are several other options, including a version of InnoDB for those who are nostalgic for MySQL. You can get all of the belts and suspenders with the clustering power of Riak.When it comes time to fetch the data, Riak offers to eliminate any of the errors that might appear. If two nodes end up with different versions of an object, Riak can either choose the youngest update or return both of the objects and leave the decision up to your client code. This is a very useful option for detecting potential errors in the data.There are a large number of query options. The basic architecture is map and reduce, but there is also the chance to write the functions in either Erlang or JavaScript.The project is shepherded by Basho, a company that provides both open source and enterprise versions of Riak. The open source version appears quite feature-rich. The main differences in the enterprise version are a slicker Web-based administration tool and the availability of high-speed, internode communication across data centers. And only the enterprise version can use SNMP.
Neo4J
If there's one application that's most different in this collection, it's Neo4J, a tool optimized to store graphs instead of data. The Neo4J folks use the word "graph" like a computer scientist to mean a network of nodes and connections. Neo4J lets you fill up the data store with nodes and then add links between the nodes that mean things. Social networking applications are its strength.The code base comes with a number of common graph algorithms already implemented. If you want to find the shortest path between two people -- which you might for a site like LinkedIn -- then the algorithms are waiting for you.Neo4J is pretty new, and the developers are still uncovering better algorithms. In one recent version, they bragged about a new caching strategy: searching algorithms will run much faster because Neo4J is now caching the node information.
They've also added a new query language with pattern matching that looks a bit like XSL. You can search a graph until you identify nodes with the right type of data. It is a new syntax to learn.The Neo4J project is backed by Neo Technology, which offers commercial versions of the database with more sophisticated monitoring, fail-over, and backup features.
FlockDB
If someone out there is writing code, someone else out there is complaining that the code is too complicated. It should be no surprise that some people think Neo4J is too intricate and sophisticated for what needs to be done. We know that Neo4J has truly arrived because the FlockDB fans are clucking about how FlockDB is simpler and faster.FlockDB is a core part of the Twitter infrastructure. It was released by Twitter more than a year ago as an open source project under the Apache license. If you want to build your own Twitter, you can also download Gizzard, a tool for sharding data across multiple instances of Flock. Both tools are ready and waiting to run in a JVM.Although many of us would call FlockDB a graph database because it stores relationships between nodes, some think that the term should apply only to sophisticated tools like Neo4J. Did someone start following someone else? Well, you can link up Flock's nodes with data such as the time that the relationship began. That part is like Neo4J. Where Flock differs is how deeply you can query this data.
FlockDB takes a pair of nodes and gives you the data about the connection. Everything else is up to you. Neo4J not only enables all types of graph-walking algorithms, but it provides them as services. FlockDB uses the word "non-goal" for these multihop queries, meaning that the developers have no interest in supporting them.The code is pretty new, and it doesn't seem to be attracting the same kind of widespread attention as some of the other projects. All of the recent commits have come from Twitter employees, and I wasn't able to find anyone offering FlockDB hosting as a service. FlockDB still seems to be mainly a Twitter project.