
U.S. Looks to Reclaim Supercomputing Crown From China, But Only 1.7PB RAM and No Local HDs?


Yesterday, the U.S. Department of Energy announced a contract with IBM to build what would be, if delivered today, the most powerful supercomputer in the world.
Except it's not being delivered today. It's being delivered, according to the press release in 2017, and according to the Summit home page "Coming 2018".
I've longed blogged about how HPC systems have been stuck in the same architecture for the past two decades, and how Hadoop, which was not mired in HPC legacy, introduced the concept of data locality.
Summit continues the same basic architecture of compute and storage separated. Now Summit does introduce a caching layer between the two called a Burst Buffer of 800GB, but there is no substantial non-volatile local storage as would be found in a Big Data system.
HPC and Big Data are converging due to data sizes increasing in the scientific supercomputing realm. I'm not the first or only to note this. A significant 2014 PhD thesis Towards Supporting Data-Intensive Scientific Applications on Extreme-Scale High-Performance Computing Systems details a five-point HPC architectural change to bring the best from the Hadoop world, with a quantified result of not only a 30x speedup over conventional HPC GPFS, but more importantly linear scaling of bandwidth looking toward exascale computing.
The five hardware/software co-design architectural changes proposed by Dongfang Zhao in his Illinois Institute of Technology thesis are:
1. FusionFS: Distributed Metadata and Efficient Network Protocols
A weakness of HDFS is that the "metadata management" (i.e. the list of available files) is handled by a single machine, the NameNode, which creates a bottleneck. The MapR distribution of Hadoop has implemented distributed metadata management since 2011 in their custom version of Hadoop, and FusionFS happens to do something similar. FusionFS does something else, though. It eschews TCP and builds its own faster protocol based on UDP.
Even GPFS (which the Summit press release says it uses) has metadata bottlenecks, yet FusionFS scales linearly to at least 1024 nodes and provides a 100x speedup compared to GPFS for metadata bandwidth.
(All images are from Zhao's PhD thesis.)
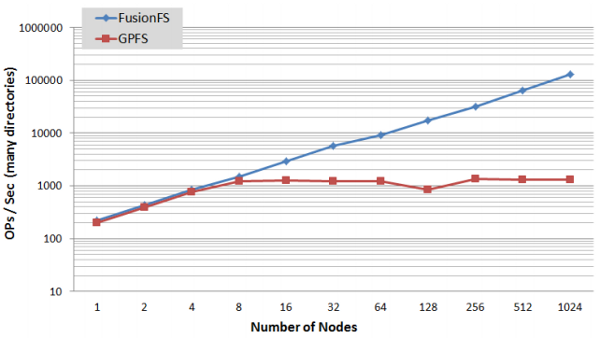
As regards regular I/O (as opposed to just metadata), FusionFS provides a 30x speedup over GPFS as shown below.
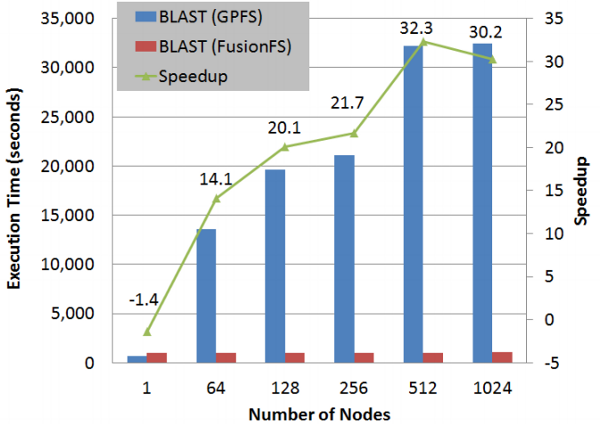
2. Caching Layer Between Parallel Filesystem and Local Node Storage
Zhao proposes a caching layer called HyCache. Presumably, this is not unlike Summit's Burst Buffer. However, Zhao takes HyCache further and also proposes HyCache+ which coordinates the caching intelligently between the nodes. I wasn't able to find enough information about Summit's Burst Buffer to determine if it has this kind of inter-node caching cooperation.
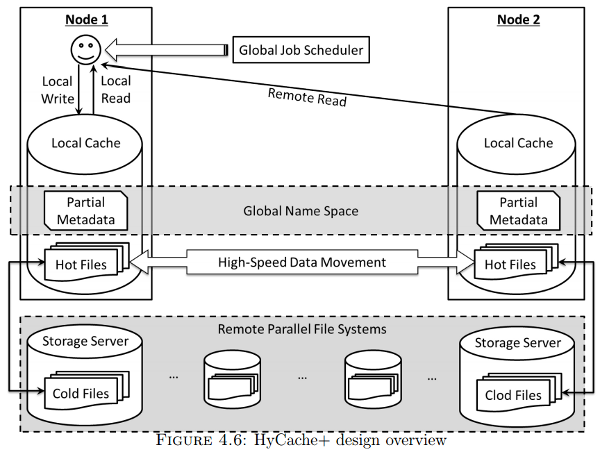
In the diagram above, Node 2 snoops Node 1's cache without having to go out to the global parallel file system or rely on its own local cache.
3. Splittable Compressed Files
Zhao describes what he calls "chunks" in compressed data files, which include reference points from which decompression can commence, thus providing close to random access, as illustrated below.
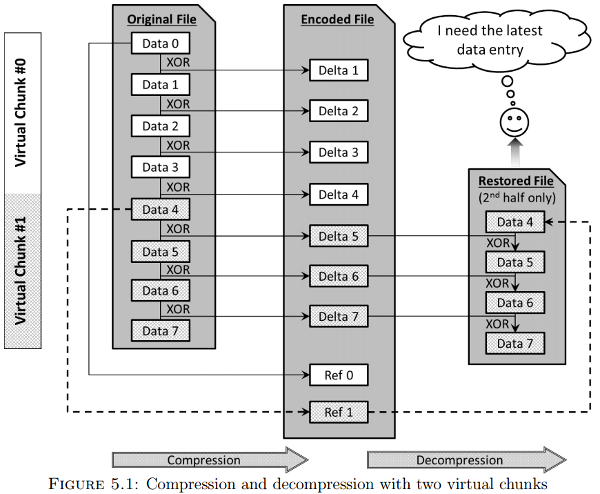
This seems close to the Hadoop concept of splittable compression files, such as are supported by the bzip2, LZO and Avro compression schemes. But perhaps the concept is new to the HPC world. If it is new to HPC, it's a good question whether Summit will support it.
4. GPU to Compute RAID-Style Parity
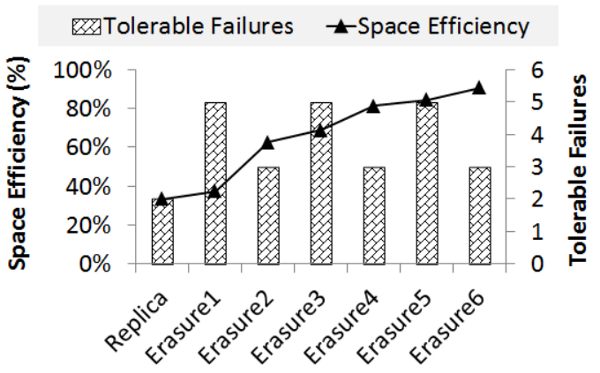
HDFS typically stores each file three times for redundancy, i.e. with a 200% overhead (i.e. 33% overall storage efficiency, meaning one-third of total storage is actually available for real data). RAID-5, in contrast, typically has just a 25% storage overhead for its parity information (i.e. 80% storage efficiency). There are proposals to add RAID-5 style error-correcting algorithms to HDFS, but adoption has been hampered by algorithmic complexity and CPU burden. Zhao proposes using GPUs to compute parity.
The most efficient parity scheme Zhao proposes, "Erasure6" has a 90% efficiency while being able to correct three errors, compared to HDFS's two correctable errors in its typical triple-replication.
5. Provenance Metadata
Not related to performance, but rather an increasing need in both scientific and business Big Data applications, Zhao proposes a first-class mechanism to record data provenance. Zhao provides motivation for provenance centered around verifiability, but it seems to me it might also be useful for lazy-processing paradigms such as Spark that store checkpoints.
Summit: Conservative Evolution from Conventional HPC
Even the RAM per node of 512GB for Summit seems conservative for a supercomputer destined to be the most powerful in the U.S., especially one to be delivered in 2018. With Summit's 3400 nodes, that's 1.7PB, which seems like a good amount for a 2014 Fortune 50 Silicon Valley company, but seems like it might be small come 2018 for a DOE supercomputer. Summit's 800GB/node non-volatile storage seems especially skimpy given the long-recognized need for data locality in HPC and advanced designs such as Zhao's described above that not only bring the best of Hadoop and HPC together, but go far beyond that marriage. Zhao's proposed system assumes substantial local non-volatile storage, that Summit is apparently being designed without.
Summit is a conservative evolution of 20+ year-old HPC design, and it seems unlikely that it will put the U.S. back on top when it is finally delivered in 2018.