
The End of Data Science As We Know It

That Data Science is "Dead" has become a meme lately, with even the venerable Vincent Granville from datasciencecentral.com lamenting offshore "analytic professionals" available for $30/hour.
Much of this is simply Data Science coasting into the "Trough of Disillusionment". Gartner's 2013 Big Data Hype Cycle has Data Science just starting to climb the "Peak of Inflated Expectations," but I say from the evidence this past week that it has definitely already passed that peak and has started slipping into that "Trough of Disillusionment".
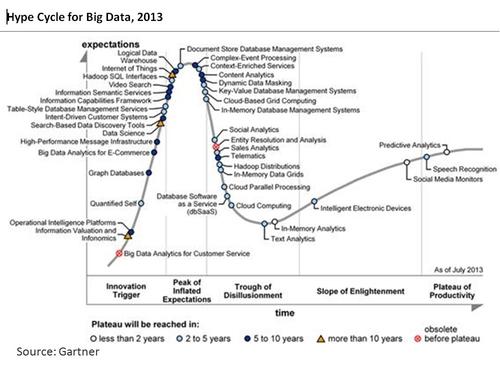
The Gartner chart posits that Data Science won't reach the "Plateau of Productivity" for more than another ten years. I think that's about right.
But there is truth in both Miko Matsumura's Slashdot post and Vincent Granville's Data Science Central post. There is a truth in there that they only just touched on, and it is part of a contrarian opinion I've been developing over the past few weeks that many disagree with me on, including other DSA board members.
With Coursera pumping out experts in Machine Learning, Statistics, Data Analytics, R, and Bayesian Networks, and with R and IPython Notebook having available these advanced algorithms pre-canned and ready to use, self-proclaimed "data scientists" -- or at least data analytics professionals -- will be a commodity, as Vincent Granville has already observed.
There is another big piece that is changing, and that is the paradigm shift away from the "Data Lake" (aka "Hadump") toward real-time ingest. In the Data Lake scenario, data is messy and requires a data scientist to intelligently deal with missing values and design experiments and quasi-experiments. It's the proof of concept phase in any new Big Data endeavor.
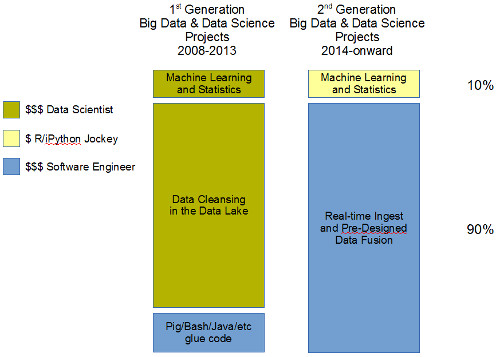
In real-time ingest scenario, data is clean -- or at least cleaner -- by design. Disparate data sets from multiple ingest points may be fused together, but it is by advance arrangement and engineering. The task of data cleansing, which is always 90% of the work involved in data science, thus is transferred from data scientists in first generation Big Data and Data Science systems over to software developers.
And that type of software development isn't the easy type -- it's clustered, parallel, and performance-driven. It's not the sort that's easily off-shored, especially since it involves integration with existing corporate data sources.
The reason for the shift from 1st generation to 2nd generation is that once insights are gleaned from 1st generation systems, consumers of those insights start demanding more up-to-date tracking, meaning real-time. The timeline depicted above of course is overly simplistic. Not only are different companies at different stages of adoption of Big Data and Data Science, but there will always be a demand for fishing expeditions within the Data Lake, but to a much lesser extent compared to the deluge we are in now that was sparked by the realization that storage is cheap enough now to not have to throw away data.
In the current era of second generation systems, where R, IPython Notebook, and machine learning software libraries are available, reliance on top-notch data scientists isn't actually taken to zero as I have depicted above. They're still needed to set direction, validate results, and perform the occasional fishing expedition as new data sources become available and come online. But they're a smaller portion of the team going forward.
Overall, the demand for top-notch Data Scientists I predict will still continue to grow. As we continue toward the Plateau of Productivity, every organization will need Data Science in order to remain competitive. But due to automation and due to clean-data-by-design of second generation systems, their numbers will be dwarfed by the number of software developers required. The number of teams requiring Data Science expertise will grow as we reach the Plateau of Productivity, but the portion of Data Scientists within those teams will shrink. And they may need to add Social Sciences to their expertise to remain competitive.
Comments
kenfar
Thu, 2014/03/06 - 8:54pm
Permalink
Drowning in the data lake
Michael, I agree with some of your points here. In particular, I think the data lake concept is fatally flawed: it's optimized to allow software engineers to avoid unglamorous data validation & transformation, allows them to focus on the sexy scaling bits of the problem, and to leave the challenges in data consumption to others.
And it's based on the notion that we can easily use valuables we carelessly toss into a dump later on. The reality is that undocumented data quickly becomes useless over time as institutional knowledge, documentation and software used to produce it disappear or become too difficult to track down.
And finally, it ignores what we've understood well for twenty years - that since data analysis is highly iterative, and frequently repeated it's best to clean and transform the data once rather than twenty+ times.
So I think it's a safe assumption that simple economics will win out here and we'll see a resurgence of interest in an investment in cleansed and curated data. But I think we need a better name than real-time ingest. Assuming that cleansed data is historical, integrated and versioned then we're talking about a data warehouse -which can be real-time, non real-time, or "right time". Maybe it just needs a naming upgrade? How about 'Lake House'?
michaelmalak
Fri, 2014/03/07 - 1:58pm
Permalink
The proper term is Lambda
You're absolutely right that real-time ingest is only half the story, with curated historical data being the other half. The combination of the two has been coined the "Lambda architecture" by Nathan Marz, and as I mentioned in this past Meetup, Druid from Metamarkets can give you "Lambda in a box". This is actually the topic of my upcoming blog post next week :-)