
Druid: Lambda in a Box

Nothing earth-shattering new in this blog post, but in light of last month's presentation by Wayne Adams on Druid Data Ingest and my recent blog post The End of Data Science As We Know It, there have been some questions about what is Druid and what is Lambda Architecture, so this is a quick summary in a single blog post.
Druid is Lambda in a box.
The term Lambda Architecture, illustrated below, comes from Nathan Marz, creator of Apache Storm, and author of Big Data: Principles and best practices of scalable realtime data systems due in October, 2014 but with early access chapters available now.
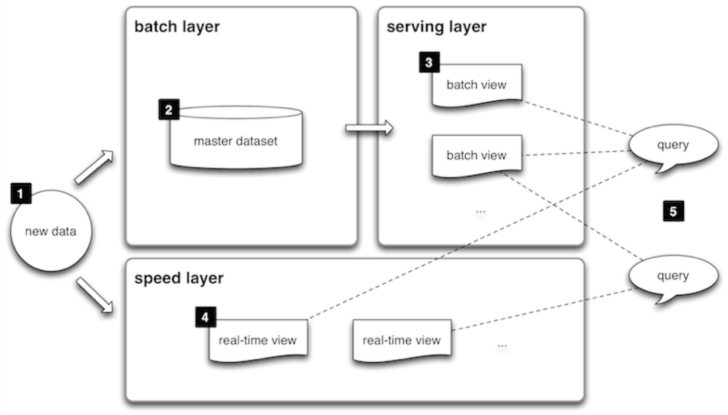

In short, Lambda architecture provides a unifying architecture that handles two use cases simultaneously: off-line manual batch analysis of historical data, and on-line monitoring, alerting and dashboarding of live data (plus making live data available to manual analysis/triage, with possibly some limitations). The illustration of a Druid cluster below comes from Metamarket's Strata 2014 presentation last month, which was just put out on speakerdeck.com.
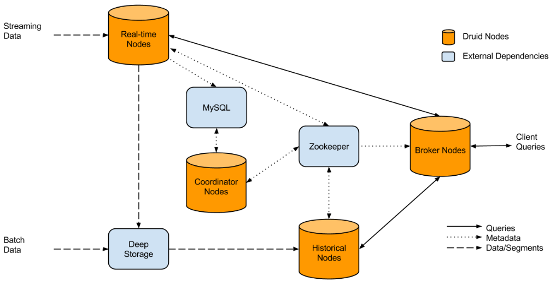
The magic in the above is that a query submitted to the Broker Node on the right side of the diagram above hits both the historical and real-time data simultaneously and seamlessly.
Others have had to cobble together home-grown solutions, such as with Redis and PostgreSQL, to provide the combination of real-time and historical data stores. But Druid gives you an entire Lambda architecture in a single platform.
Now Druid doesn't do everything. Although it does have some advanced features like HyperLogLog for approximating cardinality in real-time, the Druid query language, which is expressed in JSON and is far from SQL, is limited in the complexity of queries it can execute.
My fears a year ago about the longevity of Druid, given that it seemed to have a single primary author, Eric Tschetter, working for a company for which publishing open source software was not its core mission, has turned out to be thus far unfounded. Metamarkets is continuing to support Druid even though Eric has moved on from Metamarkets, and Eric is still active on the Druid mailing list.
Druid is good enough for Netflix to use in production.
As for comparison to the Berkely Data Analytics Stack, one can query historical data with Shark and one can route pre-programmed computations to a dashboard with Spark Streaming, but there is no out-of-the-box way to ad-hoc query that real-time data without having that data hit HDFS first -- which makes it not real-time anymore. But the Spark stack is more mature, more flexible, is a comparive joy to query against using Scala and HQL as compared to JSON for Druid, and has been proven out to 100-node clusters at Yahoo! BDAS also sports machine learning and graph processing out of the box.
