
Batch vs. Real Time Data Processing


Batch data processing is an efficient way of processing high volumes of data is where a group of transactions is collected over a period of time. Data is collected, entered, processed and then the batch results are produced (Hadoop is focused on batch data processing). Batch processing requires separate programs for input, process and output. An example is payroll and billing systems.
In contrast, real time data processing involves a continual input, process and output of data. Data must be processed in a small time period (or near real-time). Radar systems, customer services and bank ATMs are examples. Real-time streaming analytics has the potential to accelerate “time to insight” from the massive amounts of data originating from market data, sensors, mobile phones, the Internet of Things, Web clickstreams, and transactions.
 While most organizations use batch data processing, sometimes an organization needs real time data processing. Real time data processing and analytics allows an organization the ability to take immediate action for those times when acting within seconds or minutes is significant. The goal is to obtain the insight required to act prudently at the right time - which increasingly means immediately (Forrester claims a 66 percent increase in firms’ use of streaming analytics according to a 2014 survey of 740 decision makers).
While most organizations use batch data processing, sometimes an organization needs real time data processing. Real time data processing and analytics allows an organization the ability to take immediate action for those times when acting within seconds or minutes is significant. The goal is to obtain the insight required to act prudently at the right time - which increasingly means immediately (Forrester claims a 66 percent increase in firms’ use of streaming analytics according to a 2014 survey of 740 decision makers).
Complex event processing (CEP) combines data from multiple sources to detect patterns and attempt to identify either opportunities or threats. The goal is to identify significant events and respond fast. Sales leads, orders or customer service calls are examples.
Operational Intelligence (OI) uses real time data processing and CEP to gain insight into operations by running query analysis against live feeds and event data. OI is near real time analytics over operational data and provides visibility over many data sources. The goal is to obtain near real time insight using continuous analytics to allow the organization to take immediate action. Contrast this with operational business intelligence (BI) - descriptive or historical analysis of operational data. OI real time analysis of operational data has much greater value.
For example, Rose Business Technologies designs and builds real time OI systems for clients to optimize customer service processes. The ROI is improved customer satisfaction and reduced churn. OI is used to detect and remedy problems immediately - often before the customer knows of the problem.
Real time OI is used in customer service centers for customer experience optimization. Recommendation applications can assist agents in providing personalized service based on each customer's experience. An organization can collect data about customers on the phone and how they previously interacted with the organization. The goal is to analyze the total customer experience and recommend scripts or rules that guide the agent on the phone to provide an optimal customer interaction with the organization - leading to more sales, efficient problem solving and happy customers.
Rose retail clients are starting to use real time OI to detect customer buying patterns - discovering buying patterns from historical data - then monitoring customer activity to optimize the customer experience. This leads to more sales and happier customers.
Real time data processing is used by Point of Sale (POS) Systems to update inventory, provide inventory history, and sales of a particular item - allowing an organization to run payments in real time.
Assembly lines use real time processing to reduce time, cost and errors: when a certain process is competed it moves to the next process for the next step - if errors are detected in the previous process they are easier to determine.
Real time OI can also monitor social media allowing an organization the ability to react to negative activities (e.g., tweets or posts) to mitigate effects in a timely fashion before they snowball into something ugly and potentially damaging.
Other examples include real time retail dynamic pricing, real time supply chain management, social analytics for dynamic selling and brand management, and smart utility grid management.
Different real-time streaming platform architectures and designs have been developed for different analytical requirements and use cases where incoming data controls the code in contrast to usual analytics programming where code execution controls data.
Most stream processing designs have customized user defined operations for industry specific use cases such as text analytics, advanced geospatial analytics, signal processing and erlangs in a traffic network.
While open source streaming analytic products like Apache Storm and Apache Spark are popular among certain data engineers for specific use cases, at this time they are immature and lack key functionality found in the offerings of proprietary vendors. Expect both Storm and Spark to innovate and improve in the future.
Storm streaming is a record-by-record stream processing engine yet is a very technical platform that lacks the higher order tools and streaming operators that are provided by mature vendor platforms while Spark streaming is not actually a real-time streaming in the technical sense - but more of a micro-batch framework and lacks industry-proven credentials. Moreover, the Spark API layer has a different approach based on batching up events for processing - this may work well for some limited use cases, but not as well as Storm and other record-by-record stream processing engines for real-time analytics that require processing each individual record or an understanding of the data creation time.
At this time proprietary streaming analytic products are considerably more mature than open source products that require significant specialized expertise and a strong team to implement and operate.
In a Hadoop environment, the trick to providing near real time analysis is a scalable in-memory layer between Hadoop and CEP. Storm is an open source distributed real time computation system that processes streams of data. Storm can help with real time analytics, online machine learning, continuous computation, distributed RPC and ETL. Hadoop MapReduce processes "jobs" in batch while Storm processes streams in near real time. The idea is to reconcile real time and batch processing when dealing with large data sets. An example is detecting transaction fraud in near real time while incorporating data from the data warehouse or hadoop clusters.
Below is list of batch and real time data processing solutions:
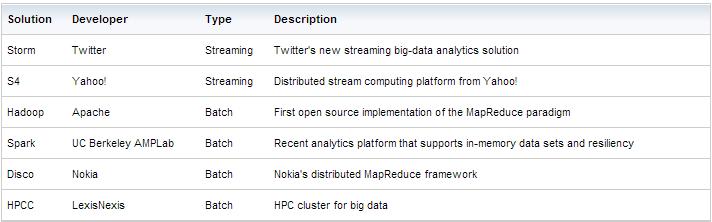
Batch and real time data processing both have advantages and disadvantages. The decision to select the best data processing system for the specific job at hand depends on the types and sources of data and processing time needed to get the job done and create the ability to take immediate action if needed.